
探索Windows:Windows错误处理和字符串处理
让我们与星光探索者一起,探索Windows吧!
Windows错误处理
在Windows API 调用时,Windows会验证我们传入的参数是否有效,然后才会执行任务。下表为Windows大部分API函数返回值的意义。
| 返回值类型 | 返回值意义 |
|---|---|
| VOID | 此函数不会调用失败,但只有极少数 Windows函数返回值类型为 VOID |
| BOOL | 如果函数失败返回0,否则返回一个非零值。因此在判断API是否调用成功时,不应该判断返回值是否为 TRUE,而是判读是否为FALSE |
| HANDLE | 如果函数调用失败,返回NULL或INVALID_HANDLE_VALUE,这取决于文档说明。否则返回一个可以操纵的对象 |
| PVOID | 失败返回NULL,否则返回一块内存地址 |
Windows API是通过返回值来表明函数的调用成功情况的。当Windows返回错误代码时,我们就可以知道为什么函数调用失败。当Widnows检测到错误时,他会使用线程本地存储区(thread-local storage)的机制将发出调用的线程(calling thread)关联在一起,这种机制使得我们在不同的线程调用GetLastError函数时,都会得到相应的近期发生的错误结果,并且不会互相干扰。
1 | DWORD GetLastError(); |
此函数返回上一个函数调用时设置的线程的32位错误代码。关于这32位的错误代码,我们可以在WinError.h头文件找到定义的相关错误代码列表。例如 ERROR_SUCCESS (调用成功时返回的错误码),ERROR_INVALID_FUNCTION,ERROR_ACCESS_DENIED
在调用函数失败之后,应马上调用GetLastError,因为假如又调用了另一个Windows函数,这个值很可能会被改写,例如,成功调用Windows API的函数可能会用ERROR_SUCCESS改写。
我们可使用FormatMessage函数 ,将错误代码格式化成一个字符串。
此外,我们可以使用Visual Studio的调试工具,在Watch窗口监测 $err,hr的值,可以看到调试过程中WindowsAPI的调用情况
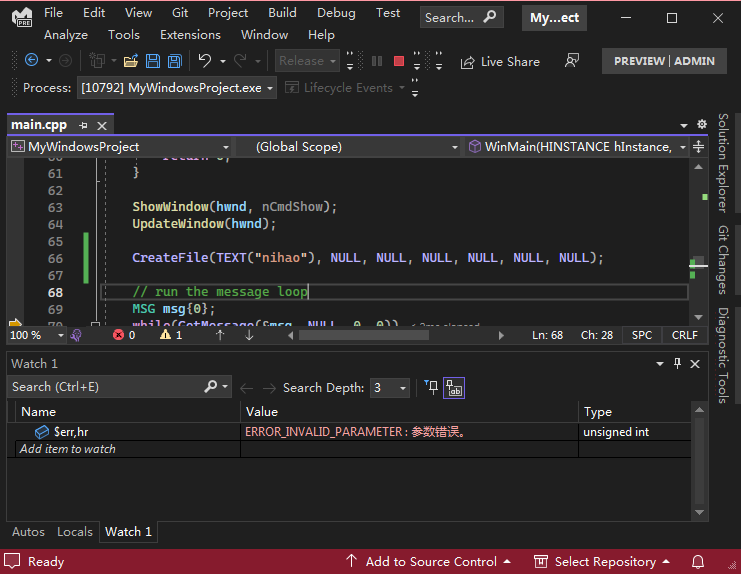
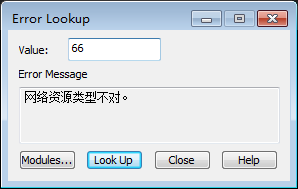
Visual Studio还提供了很多小工具。其中Error Lookup,它可以将错误代码转成相应文本描述
Error Lookup工具界面
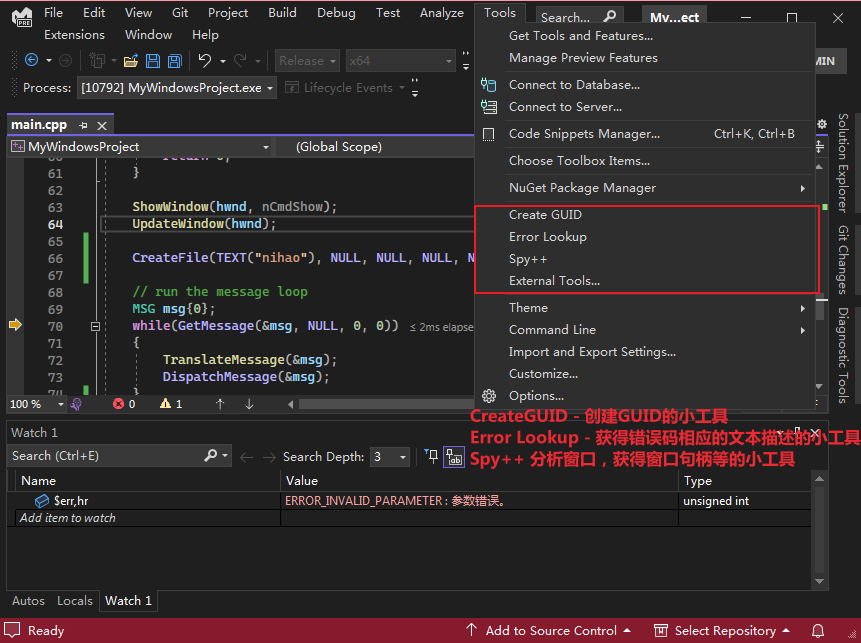
在这里可以找到这些小工具
我们可以调用SetLastError函数 ,来设置错误信息。然后使自己的函数返回FALSE,NULL或其他值来表示错误。这样我们就可以封装自己的类似Windows风格的API
1 | VOID SetLastError(DWORD dwErrCode); |
Windows字符串处理
字符串处理是编程中必然会遇到的问题。随着Microsoft Windows在世界各地的流行,微软已逐步将眼光投入国际市场。缓冲区溢出错误(这是处理字符串的典型错误),已成为针对应用程序乃至整个操作系统组件发起攻击的媒介,微软不断从内部和外部主动出击,提高Windows的安全水平。
我们知道,C/C++用char数据类型来表示一个8位的ANSI字符(不一定是ASCII字符)。微软的编译器早期定义了一个内建的数据类型wchar_t(早期被定义为unsigned short,现在已成为基本数据类型),现在wchar_t用来表示UNICODE字符。
1 | // 声明ANSI字符和ANSI字符串方式如下 |
前缀L表示此字符或字符串应该被编译成Unicode字符。为了与C语言进行区分,Windows开发团队在WinNT.h中定义了该数据类型
1 | typedef char CHAR; // An 8-bit character |
因而,在Windows开发时,我们应多使用Windows基本数据类型。
在之前的探索中我们知道,在CreateWindowEx函数调用过程中,会根据当前程序使用的字符集,来选择调用的版本是CreateWindowExA还是CreateWindowExW。我们那个时候是直接使用TEXT宏来让编译器自动帮我们把字符串转成调用相应版本时的字符串相应类型。
自Windows NT起,Windows所有版本都使用Unicode构建。也就是说,所有核心函数都使用Unicode字符串,不使用ANSI字符串。因而,Windows的API在处理ANSI字符串时,都会将其转成Unicode字符串,因此使用ANSI字符串时,应用程序会需要更多内存,运行速度较慢。为了更高效的应用程序,我们可一开始就使用Unicode字符串。
C运行库中,有很多处理Unicode字符和ANSI字符的函数。例如使用strlen获得ANSI字符串的长度,wstrlen获得Unicode字符串的长度,_tcslen获得tchar类型的字符串长度。这些函数都存在一个特点,没有提供缓冲区的长度,导致他们并不知道会不会破坏内存。上文已经提到过相关内容,因而现在使用Visual C++时,微软的编译器都会告诉你要使用安全版本的C运行库字符串处理函数(带_s后缀的),这些函数都会带一个缓冲区大小的参数。在调用这些安全的函数时我们应该使用 _countof(stdlib.h中定义此宏) 来计算缓冲区大小,而不是使用sizeof。 我们可包含strsafe.h头文件,获得更多的字符串处理函数,包含strsafe.h会自动包含string.h
此外,C运行库中新添加了一些函数,用于在执行字符串处理中获得更多控制。如StringCchCat, StringCchCopy, StringCchPrintf。Cch的意思是count of character(字符个数),使用_countof计算此值。所有这些函数的返回值返回HRESULT,当返回S_OK时,函数成功执行;返回STRSAFE_E_INVALID_PARAMETER时,函数执行失败,原因是传参数NULL;返回STRSAFE_E_INSUFFICIENT_BUFFER时,函数执行失败,原因是缓冲区不够大。
Windows也提供了各种字符串处理函数,在ShlwApi.h提供了大量好用的字符串处理函数。
如CompareString此函数用来按语言习惯来比较字符串,CompareStringOridinal不按语言习惯比较字符串,但是更快
1 | int CompareString( |
我们可通过GetThreadId 函数得到当前线程的LCID。
这两个函数返回值与C语言的字符串处理函数有所不同,返回0表示失败,返回CSTR_LESS_THAN(定义为1)指示lpString1小于lpString2,返回CSTR_EQUAL(定义为2)指示lpString1与lpString2相等,返回CSTR_GREATER_THAN(定义为3)指示lpString1大于lpString2。为了稍微方便些,如果函数成功,可以用返回值减去2,来使结果与C运行期库函数的返回值一致(-1,0和+1)。
我们使用MultiByteToWideChar将多字节字符串转换成宽字节字符串
1 | int MultiByteToWideChar( |
因而,我们一般先调用一次MultiByteToWideChar函数计算转换后的字符串长度,然后分配足够的缓冲区存放转换后的字符串,缓冲区大小为调用此函数的返回值*sizeof(wchar_t),然后再调用一次MultiByteToWideChar来存放字符串。
与之对应的是WideByteToMultiByte将宽字节字符串转换为多字节字符串。
1 | int WideCharToMultiByte( |
我们可以使用IsTextUnicode函数来猜测目标文本是否是Unicode字符。
1 | BOOL IsTextUnicode( |
当然此结果不一定准确。
