
C++面向对象知识点总结
本文记录了C++面向对象的相关知识点。
面向对象初识
何为面向对象
面向过程(Procedure Oriented):在解决一个问题时,将过程拆分为解决事情的步骤,然后按一定的顺序执行这些步骤,然后解决问题。优点是性能相对面向对象高,因为对象需要构建,开销比较大。缺点是不易维护。
面向对象(Object Oriented):在解决一个问题时,面向对象会将事物抽象成对象的概念,看此问题有哪些对象,这些对象会有什么行为,什么属性,让每个对象执行自己的行为,然后解决问题。优点是易维护易复用易拓展,缺点是性能比面向过程低,但也不会非常低。对象的行为和属性称为对象的成员。
什么是对象,例如人,手机,是对象
什么是行为,例如走路,跑步,转身
什么是属性,例如人的年龄,手机的电量,人的身高
具有相同行为,属性的对象组成的集合叫做类。
参考案例:用圆规画圆
面向过程:拿出圆规,修改圆规半径,旋转圆规,结束
面向对象:圆规创建,圆规.调整自身大小行为,圆规.旋转行为,结束。
参考案例:洗衣服
面向过程:把衣服放入洗衣机,设置洗衣时间,设置洗衣模式,开启洗衣机,结束
面向对象:构造圆规,洗衣机.放入衣服, 洗衣机.设置时间, 洗衣机.设置模式, 洗衣机.运行, 结束
在C++,面向对象世界有三大特征:封装,继承,多态。
C++面向对象的基本使用
要创建一个对象,我们需要先实现一个类,武器 吗,。在C++类我们可以使用class关键字声明。注意是可以,也就是说,可以使用别的关键字声明。在文章后面的内容讲述了用union,class,struct定义类时的效果细微差别。
1 | class 类名 |
如下列示例代码
1 |
|
运行结果:
我叫张三
我的年龄18
创建一个对象的过程叫做实例化,一个对象为该类的一个实例。
面向对象:封装
我们可以使用访问权限控制符来限制对象行为和属性是否能被外界访问。我么可以使用 public, protected, private 三个关键字来限制访问权限。如不使用这些关键字,在用class声明的类里默认使用private
public 表示外界可以访问protected 和 private都表示外界不可以访问,但是protected 属性在被继承后,仍可以被子类访问,但private 修饰的,就不行。
但无论用哪种修饰符,类内都可以正常访问这些行为。可以多次使用这些修饰符
1 |
|
因此,我们尽量给对象的属性设置非public的权限防止用户直接修改我们类的属性,避免异常。然后,提供public属性的其他成员函数来替代操作对象的属性。这即为封装的意义
构造函数与析构函数
生活中,不用的东西我们都会尽量消除与自己个人信息相关的地方,也就是保护隐私。例如扔硬盘时,我们会尽量粉碎硬盘,删除相关的个人信息。公司的一些文件,销毁时使用碎纸机,尽量销毁相关信息。
因而构造函数和析构函数是帮助我们处理构造对象和销毁对象的相关工作。在栈区的对象,其构造和析构的工作由编译器保证正常完成。
语法
语法如下(注:成员函数也是可以重载的):
1 | class 类名 |
构造函数和析构函数没有返回值,但是不写void,函数名与类名同名,但不能使用const, virtual修饰函数。
析构函数不能有参数,因而析构函数不可以重载,但是构造函数可以重载,但不能使用const修饰函数。
构造函数和析构函数将分别在构造对象和销毁对象的时候自动执行,编译器保证肯定会执行。当对象生命周期结束时,对象会被析构。但是构造函数和析构函数应使用public的访问权限,要不然编译器无法构造和析构对象。在单例模式中我们将了解到限制实例化对象的方式。
例如:
1 |
|
运行结果:
对象被构建
对象被构建
对象被析构
对象被析构
对象的生命周期
对于任何类型的对象,离开自己的作用域后,就会被析构掉。
1 | int g_a; |
构造函数的分类
根据构造函数是否有参数,可分为:无参构造函数,有参构造函数
根据构造函数的意义,可分为:默认构造函数(没有参数的构造函数,也可称作缺省构造函数),复制构造函数(对象拷贝的构造函数,也可称作拷贝构造函数),移动构造函数(对象资源移动所有权时的构造函数,这是C++11语法)
下面是一些示例
1 |
|
运行结果:
默认构造函数
有参构造函数
拷贝构造函数
val: 0
val: 3
val: 0
对象被析构
对象被析构
对象被析构
默认提供的构造函数
如果你不实现构造函数,编译器会实现默认的。如果你实现了默认构造函数,那么编译器还会提供默认实现的拷贝构造函数。如果你实现了一个带参数的构造函数,但不是拷贝构造函数,编译器不提供默认构造函数,但仍会提供默认的拷贝构造函数。如果你实现了一个拷贝构造函数,那么编译器不再提供默认实现的构造函数。
默认提供的拷贝构造函数,会将自身的每个属性从一遍逐个字节拷贝到另一个对象。
例如:
1 |
|
运行此段代码,可以看到打印o1,o2的值完全一致。
但是如果我们改成这样:
1 |
|
运行代码,会发现出错,原因是重复释放堆区的内存。o2被析构时,o2的m_ptr指向的堆区内存被释放。o1析构时,由于o1和o2的m_ptr都指向同一块堆区内存,因为这是默认提供的构造函数造成的,o1又释放了一遍,因此代码出错了。
编译器默认提供的拷贝构造函数叫做浅拷贝,浅拷贝会会将自身的每个属性从一遍逐个字节拷贝到另一个对象。为了避免浅拷贝的危害,对于储存堆区数据的类,我们需要实现深拷贝。深拷贝即为,再开辟一块新的内存空间,拷贝原先数据到新的数据那里,而不是直接拷贝。
示例:
1 |
|
初始化列表
我们使用初始化列表,可以更高效地初始化类的相关属性
语法如下:
1 | class 类名 |
例如:
1 | class O |
使用初始化列表初始化对象,对象的属性会被正确的初始化,写起来比较直观。对于类内的引用类型,const类型的非静态成员变量,只能使用初始化列表来初始化这些对象。
匿名对象
使用 对象名(参数) 可以构造一个匿名对象,匿名对象由于没有名字,构造之后会被马上销毁
1 | class O |
运行结果:
构造函数调用
析构函数调用
匿名对象在之后的swap函数实现非常有用。
总之,对象的构建顺序是,先分配内存给对象,然后对象调用构造函数,对象的析构顺序是,先调用析构函数,再回收对象占用的内存空间。
静态成员
一个类的所有实例都能共享的成员变量或成员函数,称为静态成员。
静态成员变量特征:所有实例共享,编译阶段分配内存,类内声明类外初始化。
静态成员函数特征:静态成员函数只能访问静态成员变量,原因是静态成员函数没有this指针(下方内容提到了this指针的概念)
访问静态成员的方式:
- 类名::静态成员
- 先创建一个对象,然后 对象.静态成员 来访问
静态成员在某种意义上可以看成是只属于这个类的全局函数或全局变量,但是可以通过访问权限来限制外界访问这个静态成员。因此只有静态成员声明为public时,外界可以访问。
示例代码:
1 |
|
C++对象模型初步探索和this指针
C++在设计类时,经过了努力有了现在的对象模型。最终,C++标准规定,一个类如果什么成员变量都没有,即空类占1字节。只有成员变量储存在对象身上,其他的成员函数不储存在对象身上。
那么现在出现了一个问题,所有对象都调用同一个成员函数。成员函数是如何区分是哪个对象调用的成员函数呢?C++通过使用特殊的指针,this指针来解决这个问题。在调用成员函数时,编译器会隐含传入this指针,哪个对象调用的成员函数,this指针就指向谁。this指针不需要自己声明,因为编译器在默默帮助你。
this指针的用途:
- 使用this指针解决冲突。当函数形参或局部变量与类成员变量重名时,会产生名字冲突。
- 返回指向自身的地址或引用。再之后的高深技术学习中,我们可以运用this指针防止自己给自己赋值,实现累加操作等。
this指针的实质是指针常量,指针的指向是不可修改的。相当于类名 const * this;
例如:
1 | class Object |
空指针或野指针调用成员函数
空指针或野指针也是可以调用成员函数的,因为编译器不限制。这种方式调用时,在运行时,可能会出错,也可能不会。出错的时候,可能是因为使用了this指针.
空指针:指向地址0的指针
野指针:指针指向的位置是不可知的(随机的、不正确的、没有明确限制的)
1 | class Object |
我们为了使show_val成员函数仍正常输出,使用如下措施保证其不报错。
1 | // 修改show_val函数保证正常输出 |
运算符重载
我们可以重载一些运算符,使他们为我们所用。我们可以重载大多数C++运算符。
特别地,对于像++运算符,有前置和后置两种形式,对于前置的++运算符,我们重载时需要添加一个int类型的站位参数来区分。
在类内部使用运算符重载方式:
1 | 函数返回值 operator运算符 (参数列表) |
例如
1 | class MyClass |
当一个类重载了小括号运算符时,这个类通常被称为仿函数,因为小括号和函数调用运算符很像,并且也有类似的行为。
如果我们想要自己的类型可以任意的转换,我们可以定义类型转换函数,下面是在类内部定义类型转换函数方式。
1 | operator 将转换的类型() |
如:
1 |
|
运行结果: false true
成员常量和常函数
成员常量是不可修改的,如果想要初始化成员常量,需要用初始化列表初始化。
成员函数用const修饰之后被称作常函数,常函数不可以修改成员属性,但是如果给成员属性用mutable关键字,常函数中仍可以修改
声明对象时用const,此对象被称为常对象,常对象只能调常函数,此时this指针的意义即为 const 类型名 const * this;
1 | class MyClass |
友元
有时我们希望全局函数,其他类,或其他类的成员函数也可以访问我们的非public权限的成员,我们应该怎么做呢?答案是使用友元。友元,使用friend关键字,friend即朋友的意思。
友元的三种方式:
- 全局函数做友元
- 成员函数做友元
- 类做友元
友元案例:
1 | class MidClass; |
面向对象:继承
继承初步
看这个网页https://ustarry.github.io/,我们可以看到,在这个网页的 首页,领地,工具这些页面中,都有相同的标题栏,但是网页的内容不同。
像这样,我们可以通过继承的方式,让一个类继承一个类,继承后的类拥有原先类的所有行为,但可以有自己独特的行为,这样可以减少代码量,这就是继承的优势
如果类B继承类A,那么B叫做子类,A叫做基类。继承语法
1 | class 子类名 : 继承方式 基类 |
继承方式有public, protected, private三种,如果不指定继承方式,在继承用class声明的类时默认使用private。使用public方式,父类的public属性的仍然在子类表现为public,protected也表现为public,private属性不可以访问
用protected方式,父类的public属性在子类表现为protected,protected属性表现为private,private属性的直接不可访问
用private方式,父类的public属性变为private,父类的其他属性再也不可以访问
例如上面的案例,我们就可以通过继承来减少代码:
这是不用继承的实现方式
1 |
|
使用继承之后:
1 |
|
上面两种代码效果等价,但是很明显第二种代码更少。这即为继承的优势
继承的父类子类构造顺序和多继承
继承之后,是先构建父类还是先构建子类呢?直接说结论,先构建父类,再构建子类。析构的时候,先析构子类,再析构父类。
C++允许一个类继承多个类,多继承语法如下:
1 | class 子类: 继承方式1 父类1, 继承方式2 父类2 ... |
如果父类和子类在某些成员上重名了,那么默认使用子类的属性,如果一定要使用父类的成员,使用 :: (作用域运算符) 强制使用父类的成员。
如,类Son是类Base的子类,这些类都定义了val属性。假设我们已经有了子类的一个实例叫做obj。如果我们想在子类访问子类的val属性,直接 obj.val,或使用作用域运算符obj.Son::val。用父类的属性,则必须obj.Base::val
当然,作者不建议使用多继承。
菱形继承和虚继承
如果有类AA,BB,CC,DD,类AA有long long的,m_data1, m_data2,m_special属性。这时我们使BB继承了AA,CC继承AA,DD多继承BB和CC。像这样的继承,如果我们画出继承图像,图像看起来像菱形,因此这种继承方式被称为菱形继承,也称为钻石继承。我们来尝试输出D占的字节。
1 |
|
上述代码中,我们期望应该只占三个long long的和。然而,在作者的计算机处运行,结果居然占了48字节!
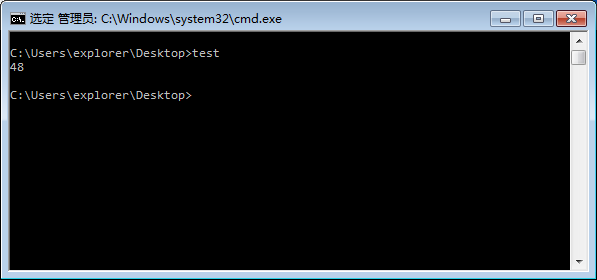
这是为什么呢?在这里我们可以使用MSVC的工具集来看一下这个类D在内存中的布局。
进入到存放此代码的目录,调出命令行,输入下方指令( 注意是 d1不是 dl )
1 | cl /d1 reportSingleClassLayoutDD test.cpp |
这段指令将查看test.cpp文件中类DD的内存布局模型,如果你想查看666.cpp文件中类Monster的内存布局模型,输入cl /dl reportSingleClassLayoutMonster test.cpp
作者看到DD类的内存布局如下:
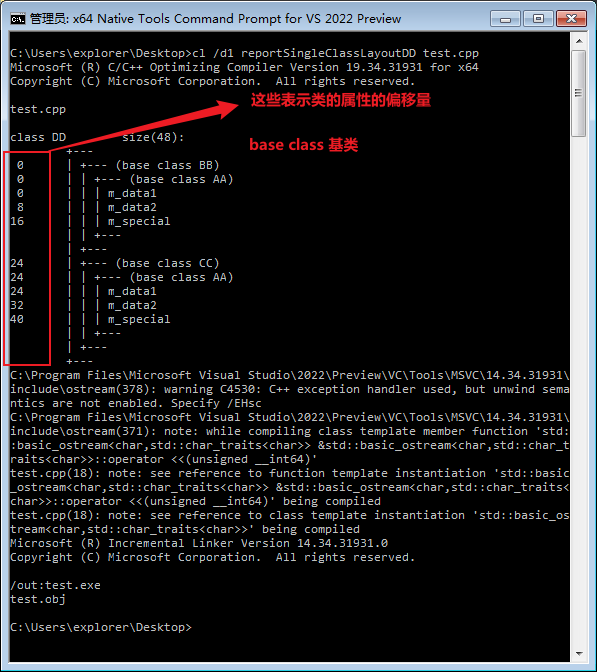
可以看到,如果像这种方式继承,我们浪费了很多字节。因为m_data1,m_data2,m_special本来就要一份就好,现在有这么多份。我们应该怎么做避免浪费呢?使用虚继承就可以了!看下列改进的代码
1 |
|
看一下这种状况下的内存布局,发现占用更少了!

原理到底是什么呢?原来,使用虚继承后,就改成继承 vbptr(virtual base pointer,虚基类指针),而不是直接继承m_data1, m_data2, m_special。然后vbptr指向叫 vbtable(virtual base table虚基类表) 的东西,每一个进行虚继承的类,都会生成一个叫vbtable的表,这个表储存的是偏移量,这样就可以导致m_data1, m_data2, m_special只需要储存一份,BB,CC类使用vbptr指向的偏移量,偏移到储存m_data1, m_data2, m_special的位置就可以读取数据了,这样就形成了数据的共享,减少了占用。
当然并不推荐进行多继承,了解一下原理也是不错的。
面向对象:多态
多态认识
多态,顾名思义,即为多种形态。多态可以分为静态多态和动态多态。
静态多态:编译阶段确定调用函数的类型,即地址早绑定。例如函数的重载,运算符重载,模板(如CRTP技术)
动态多态:运行时才确定函数的类型,即地址晚绑定
来看下列代码:
1 |
|
这个问题似乎非常难解决。但是我们应该考虑到,但凭一个地址没有办法分辨是哪个类型的对象调用的say函数,void to_say(Base*)函数定义参数类型为Base*,因而,都调用的是Base::say函数。
但是,如果我们想传入哪个类型的对象,to_say就执行哪种类型的say函数。那么应该如何做呢?使用virtual关键字定义虚函数。
1 |
|
这样之后,我们想传入哪个类型的对象,to_say就执行哪种类型的say函数。不信可试一下。使用虚函数,这样就可以使得这种想法实现了。
动态多态满足的条件:子类继承父类,并重写虚函数,并且传参数时传指针或者引用。
关于重写和重载的认识
- 重写:函数返回值类型,函数名,函数参数列表完全一致
- 重载:函数名一致,但函数参数列表不同
虚函数原理
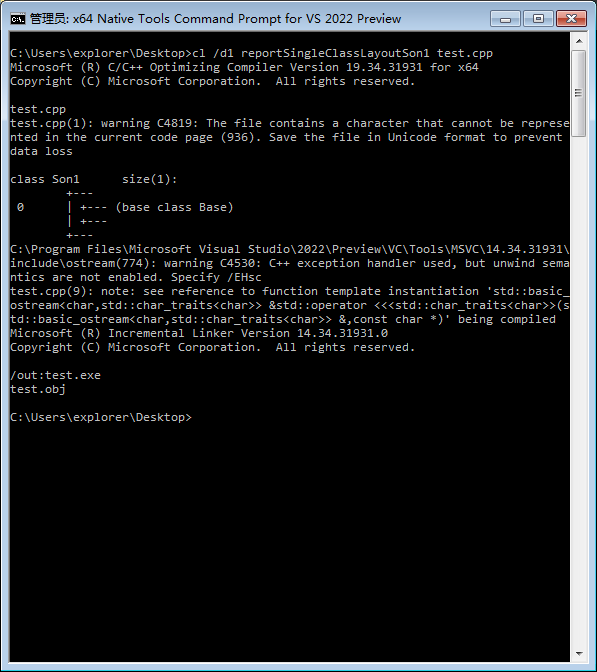
我们使用MSVC的开发者工具分别查看上方未使用虚函数时,和使用虚函数时的类Son1内存布局。
之前
之后
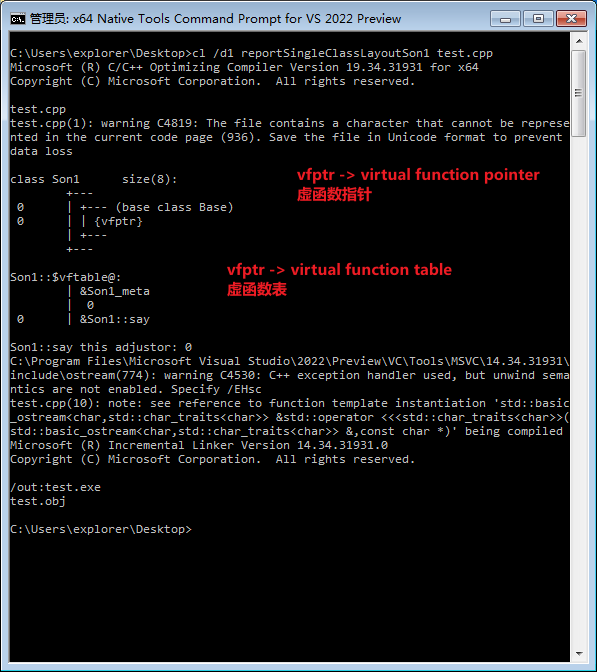
我们可以清晰地看到,之后类Son1中多了**vfptr(virtual function pointer,虚函数指针),虚函数指针指向vftable(virtual function table,虚函数表)**。每个类都有自己的虚函数表,虚函数表储存了类的所有虚函数的地址。如果本类重写了某名称的虚函数,那么本类的虚函数表的该名称的虚函数地址将使用为自己重写的函数的地址,否则就用父类的虚函数地址。函数调用时,通过读到对象的vfptr获得相应要调用的成员函数的地址,然后跳转到该地址执行代码。 每个子类都有不同的虚函数表,因此,传每个子类的实例上去,都会调用相应的函数,这就是虚函数原理了。
纯虚函数
有时,我们的父类的虚函数不需要写任何代码,但是父类调用又没有任何意义,我们想强迫子类必须重写父类的虚函数。这时,我们就可以使用纯虚函数了。语法如下:
1 | class 类 |
有一个及以上纯虚函数的类叫做虚基类,虚基类不可以实例化对象,因为如果要调用虚函数,虚基类可没有办法实现。这时,必须要子类继承,并重写父类的所有纯虚函数,如果没有重写完,子类也不可以实例化。
1 | class Base |
更进一步的面向对象编程
union,class,struct定义类的区别
在C++,union,class,struct都可以定义类,区别如下:
union 所有的成员对象共享同一内存,他们的起始地址是相同的。一个union可以有多个数据成员,但是在任意时刻只有一个数据成员可以有值。当我们给union的某个成员赋值之后,该union的其它成员就变成未定义的状态了。分配给一个union对象的存储空间至少要能容纳它的最大的数据成员。union的成员默认访问权限是public,可以设置其他的访问权限,可以有静态成员,非静态成员函数,自定义的构造函数和析构函数,不能有虚函数。但是union的成员必须是POD类型。union也不能被继承。
class和struct仅存在默认访问权限和默认被继承方式不同。对于class,默认访问权限和默认被继承方式都是private,而对于struct,默认访问权限和默认被继承方式都为public。
C++11下统一的方式给对象初始化
对于给对象初始化,有三种形式
1 | int a1 = 0; |
这三种方式都可以正确的给变量初始化为0,但是第三种是C++11特有的初始化方式。对于给一个对象初始化,如果可能,我们可以使用小括号,或者花括号。使用花括号时,这种初始化方式为统一初始化。
统一初始化可以初始化聚合体类型,也可以初始化非聚合体类型。在初始化聚合体类型数据时,要按聚合体成员声明顺序顺序初始化聚合体的非静态类型成员变量。当然,统一初始化是不可以给静态成员初始化的。
什么是聚合体?普通数组,或者满足下方所有条件的类都是聚合体。
- 没有用户自定义的构造函数
- 没有用protected或private修饰的非静态成员变量
- 没有基类
- 没有虚函数
注意,聚合体的定义并不是递归的。换句话说,就是A如果是一个聚合体,他的成员变量可以不是聚合体,只需A自己满足聚合体的条件即可。
1 | struct MyType |
对于非聚合体,我们只需定义构造函数,来进行非聚合体的初始化。
1 | struct MyType |
但是如果一个类中有了以std::initializer_list类型为形参的构造函数,那么只要使用统一初始化,都只能调用带std::initializer_list类型的构造函数。
C++11的关键字final
我们可以使用final关键字阻止子类重写虚函数,或者使某个类无法被继承
1 | class AAA final |
C++11的关键字override
override关键字保证函数必须重写了父类函数,如果没有重写,就会报错
1 | class Base |
C++11的委托构造函数
如果我们想在构造对象时,委托另一构造函数执行部分工作,在C++11前没有办法做到,必须使用成员函数,现在我们可以直接委托构造函数进行构造的部分工作了。
1 | class Factory |
C++11的继承构造函数
有时我们可以一步到位,直接继承完父类的所有构造函数,而不复制粘贴一遍
1 | class Base |
C++11的=default & = delete
有的时候,我们想显示指定编译器生成默认的构造函数,我们就可以使用=default
有的时候,有些类我们不想让他有拷贝构造函数,但是又想有默认构造函数,我们就可以使用=delete
1 | class Base |
